Our group’s webpage is handled by a Python bot I built some time ago and which Claude Code has helped me perfect. The bot creates pages with the publications of each scientist in the group and selects those that more or less belong to the period those scientists worked with us, creating our group’s publication list.
The system works pretty well. It uses ORCId and the arXiv identifiers as sources of truth and supplements some information from Google Scholar. Unfortunately, when applying this tool we have found two problems:
- ORCId and arXiv webpages are often not maintained by their owners.
- Some scientists don’t know they even exist.
- Some publishers corrupt some DOI records with crap.
The last problem I still have not found a solution for. I am working with Claude on understanding how publishers dare to introduce MathML or MathJAX in titles and how to fix it, but hey, that’s a weekend project.
The first two problems, on the other hand, prompted me to write this little guide explaining what ORCId and arXiv identifiers are and trying to help my colleagues find ways to keep them more up to date.
arXiv identifiers
I think all scientists know what the arXiv is, so I will not explain it. However, not all scientists seem to know or understand what arXiv identifiers are, so here it goes a brief summary.
The arXiv is a huge repository of preprints and a wonderful resource to make your research accessible to the overall public. However, in such a big database there are bound to be collisions: two or more scientists with the same name, such that searching papers with those names returns mixed results.
The arXiv id solves this by creating a dedicated webpage only for your preprints. However, for this webpage to be populated, you must explicitly claim ownership of the preprints that really belong to you. Otherwise the arXiv would not be able to tell which manuscripts are yours and which belong to a similarly named researcher.
The thing is that this identification happens automatically when you submit a manuscript to the repository, because the software knows it was you who did it. But when you work with other colleagues in a shared publication, you need to claim ownership of the preprint in one of two ways:
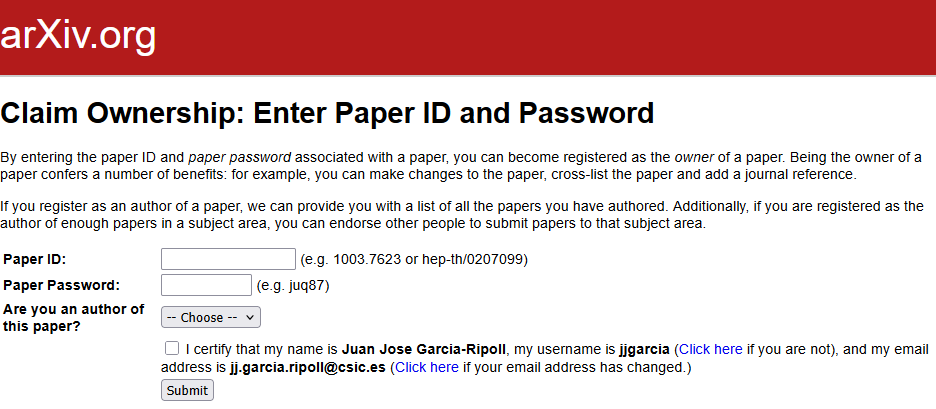
You can ask your coworkers for the password they received when the manuscript was approved and then go to the manuscript claim form and enter the code of the manuscript plus the password to declare the manuscript is yours, as shown in the capture below
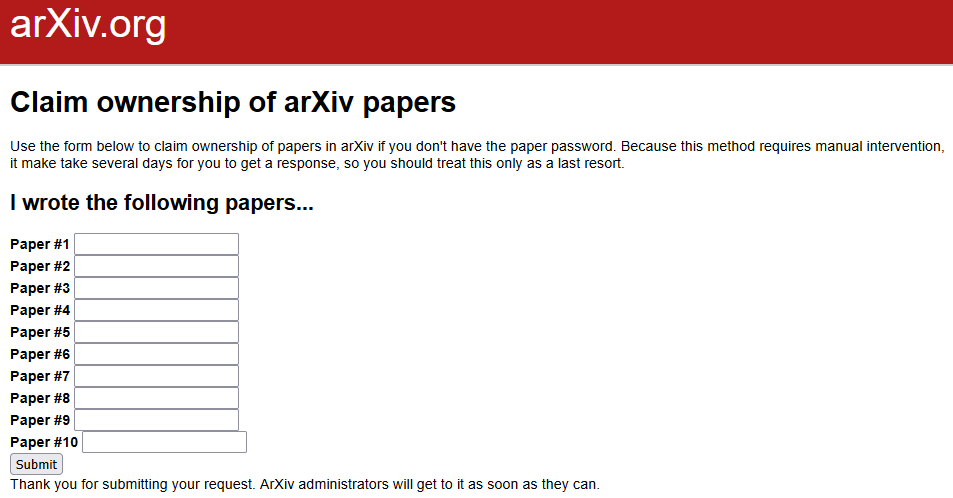
Alternatively, for manuscripts that are very old or whose password has been lost in the unending folders from a university’s webmail, you can collectively claim ownership of manuscripts based on their arXiv code. This is a labor intensive process where someone must verify your claims and it is not the recommended way.
For this list to be maximally useful, you also should make sure that your preprints are associated to published works once the referral process is complete. You do this by updating the information from your manuscripts, associating at least the publication DOI’s code, but ideally also the complete reference.

Once you do this, the association between both items (pre-print and final publication) helps software that can offer your preprint’s PDFs for publications that sit behind paywalls. It also helps software such as our group’s bot or Google Scholar to find out that the preprint and the publication belong together and they should be listed as only one item.

ORCId
The other and more official authoritative resource of information about you and your research is the ORCId webpage. This is a different beast that includes way more information than just papers: it lists previous and current positions, funding information, education, peer review activity, etc.
There is no workaround to entering most of the information yourself. ORCId cannot really know about your employers nor where you got your degrees, but there are two things that can be more or less automated.
When you publish a manuscript, most journals nowadays ask for your ORCId and ask you to confirm that you authorize to enter information on your behalf. This creates an authorization chain like the one you see below, that may be either directly with the journal or with Crossref, the scholarly record that brought us DOIs.
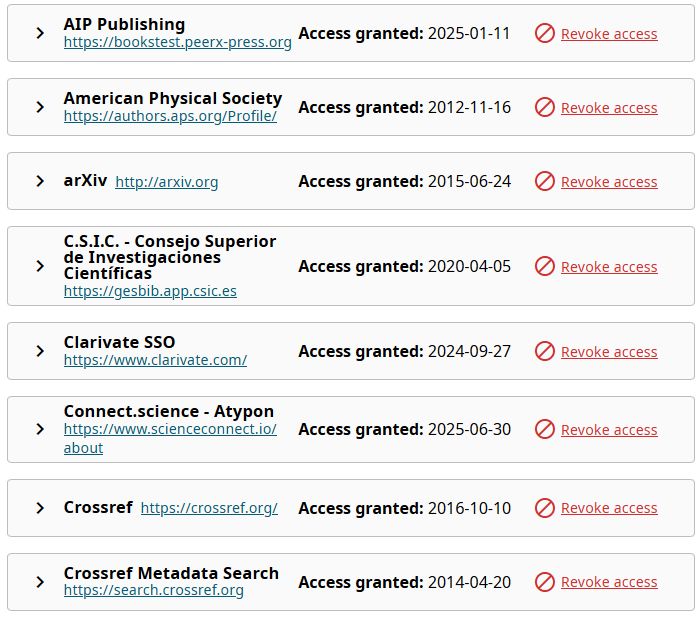
Once this link is granted, Crossref will keep your publication database up to date with papers where you are listed as an author for the journals you have authorized.
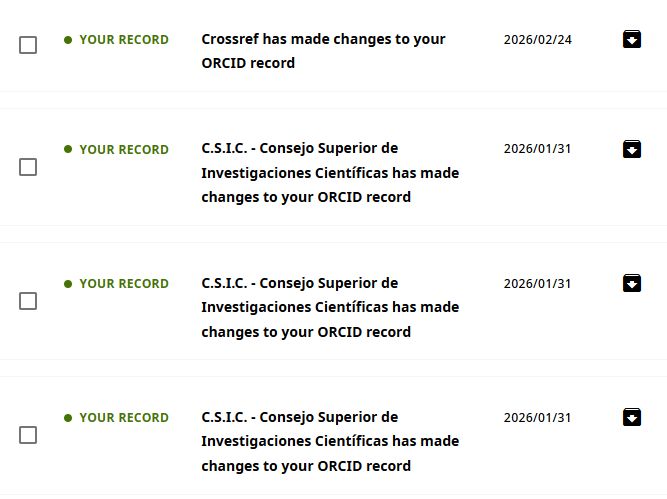
Notice however that this job can also be done by other institutions. In this case, my employer also takes care of updating my publication record. It does so because I entered the ORCId authorization in my personal profile (Intranet – Aplicaciones Corporativas – Información Personal – Mi Perfil), enabling my employer to associate publications that it identifes as mine (and theirs) and keeping that information up to date.
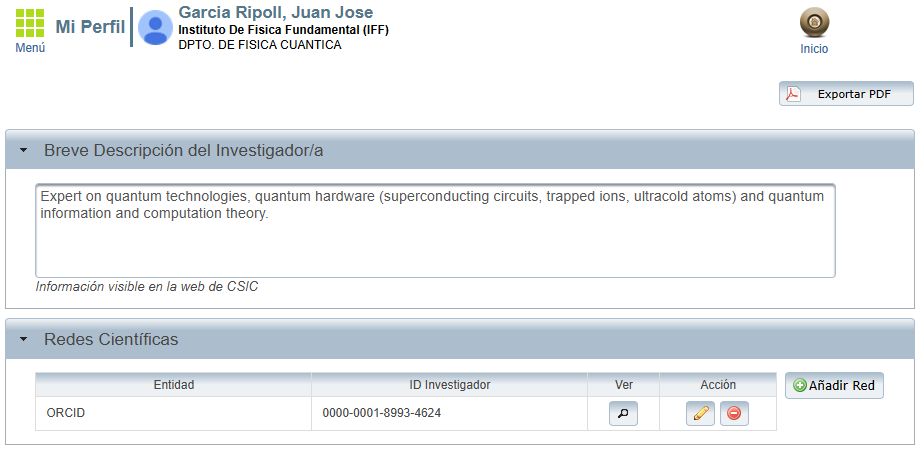
This is extremely convenient too, because it goes beyond authorizing every single journal, enabling also the inclusion of documents that are not official publications, such as institutional preprints, reports, etc., all of which have DOIs of their own.
Conclusions
I hope this information was useful for our group’s members and perhaps for other people too. We live in a new era where scientific information is both more open and more traceable than ever. This is fantastic but requires a bit of maintenance and care on your side. As someone said, help us help you.
F.A.Q.
Why not use Google Scholar?
Google Scholar is a proprietary software that is neither designed to be scraped nor used as reference database. Furthermore, information stored in Google Scholar may be unilaterally changed by system without your intevention. This causes many Scholar profiles to get rot, including publications that do not belong to the users, or records (e.g. talks in conferences, webpages, PDFs from slides) that really are not comparable to peer-reviewed publications.
Why does my publication record look ugly?
As I have said above, while there are standars for publishing DOI records using XML and CL+JSON formats, some publishers take liberties such as including equations in strange unparseable formats (e.g. MathML). We have yet to upgrade our bot to handle those corner cases.
If I supply ORCId’s to publishers, does it mean I don’t have to maintain my page?
Unfortunately, not. We have colleagues whose ORCId remained empty despite having provided this information to all publishers. One clue for you would be to verify that the journals and Crossref are linked to your ORCId account. If this is not the case, contact those publishers directly. We cannot really help you on this front.
Will you release the software for scraping publications?
Maybe, eventually. It is part currently of a scientific WordPress framework we developed for this group and which we’re trying to make more general. Whether it makes sense to refactor just the publications’ component is something we need to think about.